Over Sampling for Regression

출처 : https://towardsdatascience.com/strategies-and-tactics-for-regression-on-imbalanced-data-61eeb0921fca
0. Data Imbalance(데이터 불균형)
데이터 불균형은 현실 세계의 데이터에서 자주 일어나는 문제입니다.
데이터는 종종 편향된 분포를 보여주지만 현재 사용되는 대부분의 머신러닝 알고리즘은 각 대상 범주(분류)에 대해 균일한 분포를 가정하여 설계되었습니다.
한편으로, 많은 작업들이 타겟 값(변수)이 연속적인 값을 갖거나 무한한 값을 갖는 경우를 포함하여 (회귀), 클래스 간에 엄격한 경계가 존재하지 않는다는 것을 유념해야 합니다. (예: 나이 예측, 깊이 추정 등).
- 실생활에서 소수 클래스(minority class)가 더 중요한 의미를 갖는 경우가 많다(제품 불량, 질병 등)
- 따라서 소수 클래스의 인식률을 향상시키기 위한 방법이 필요함
- 불균형 데이터는 예측 모델링에 심각한 영향을 미침 : 일반적으로 학습 알고리즘은 대다수 클래스에 편향될 것
- 일상에서 악의적인 공격 방지, 생명 위협 질병 탐지, 모니터링 시스템에서 드문 사례 처리 등 다양한 작업들은 1:1000에서 1:5000에 이르기까지 다양한 비율로 극도의 클래스 불균형 현상이 나타남
- 따라서 극단적인 편향을 조정하고 극복할 수 있는 지능형 시스템이 필요함
이 글에서는 회귀 문제에서 불균형 데이터를 처리하는 방법을 안내하고, 각 케이스에서 사용 가능한 성능 측정 방법에 대해 설명합니다. 불균형 데이터로부터 학습하는 3가지 주요 접근법은 다음과 같습니다.
1. Data approach
2. Algorithm approach
3, Hybrid (ensemble) approach
1. Data approach
1.1 오버 샘플링(Over Sampling)
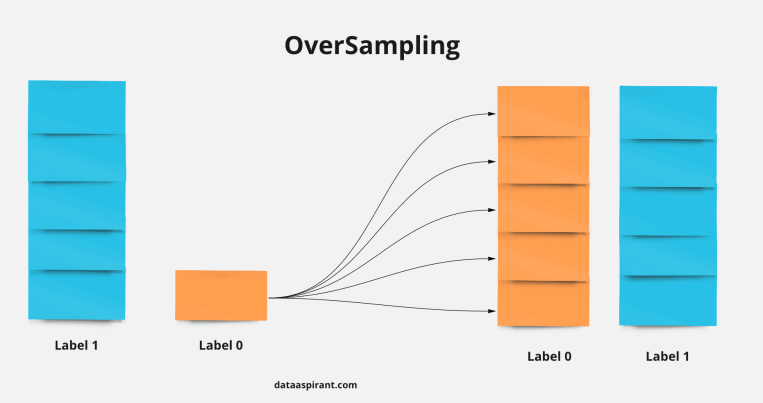
오버 샘플링(Over-sampling)은 머신 러닝 데이터 세트에서 클래스 불균형 문제를 해결하기 위해 사용되는 기술입니다.
- 일반적인 시나리오에서 데이터 세트는 한 클래스의 인스턴스가 많고 다른 클래스의 인스턴스가 적을 수 있음
- 불균형은 모델 학습이 편향되거나 잘못되게 할 수 있습니다.
- 기존 인스턴스를 복제하거나 합성 인스턴스를 생성하여 소수 클래스의 인스턴스 수를 늘려 클래스 분포를 균형있게 만듦으로써 이를 해결
- 특히 회귀 문제에서는 연속 값을 예측하는 것이 목표이며, 오버 샘플링은 목표 변수의 분포에 대한 불균형을 해결하는 데 사용할 수 있습니다. 특히 드문 또는 극단적인 값이 충분히 표현되지 않은 경우에 이러한 기술을 사용할 수 있습니다. 회귀를 위한 SMOTE와 같은 오버 샘플링 기술을 사용하면 목표 변수의 분포를 균형있게 만들기 위해 합성 인스턴스를 생성할 수 있으며, 이는 모델의 성능을 향상시킬 수 있음
1.1.1. 회귀 문제에서의 오버 샘플링
불균형 데이터 세트를 처리할 때 오버 샘플링 방법은 특히 연속적인 목표 변수를 예측하는 회귀 문제에서 중요합니다. 회귀 문제를 위한 여러 오버 샘플링 방법은 다음과 같습니다. 이러한 방법들은 합성 인스턴스를 생성하거나 기존 인스턴스를 복제함으로써 회귀 문제에서 불균형 데이터 세트 문제를 해결하고, 결과적으로 모델 성능을 향상시킬 수 있도록 합니다.
| 방법 | 설명 |
| 무작위 오버 샘플링 | 무작위 오버 샘플링은 데이터 세트의 소수 클래스 인스턴스를 무작위로 복제하는 것을 포함합니다. 회귀 맥락에서 드물거나 극단적인 타겟 값을 갖는 데이터를 복제(여러번 샘플링)하는 것일 수 있음 |
| SMOTER | SMOTER는 회귀 문제를 위한 Synthetic Minority Over-sampling Technique (SMOTE)의 적용. 데이터 세트를 균형있게 만들기 위해 연속적인 목표 변수의 소수 (드물거나 극단적인) 값에 대한 특징 공간에서 합성 샘플을 생성 |
| 가우시안 오버 샘플링 | 가우시안 오버 샘플링은 목표 변수의 가우시안 분포를 가정하여 합성 인스턴스를 생성하는 방법입니다. 목표 변수의 분포가 정규 분포라고 가정되는 회귀 문제에 적합함 |
| MWMOTE (Majority Weighted Minority Over-sampling Technique) |
MWMOTE는 소수 클래스를 고려할 뿐만 아니라 합성 샘플을 생성할 때 다수 클래스 인스턴스도 고려하는 고급 오버 샘플링 기술입니다. 이 방법은 더 균형있는 데이터 세트를 생성하기 위해 회귀 문제에 적용할 수 있습니다. |
| 적응적 합성 샘플링 (ADASYN) |
ADASYN은 소수 클래스의 분포에 따라 적응적으로 합성 인스턴스를 생성하도록 설계됨 회귀용 ADASYN의 적용은 예측 오류가 높은 영역에 중점, 모델이 더 잘 학습할 수 있도록 합성 인스턴스를 생성 |
불균형 분류 문제를 해결하기 위한 방법 중 불균형 회귀 문제에도 적용 가능한 대표적인 방법은 다음 2가지가 있습니다.
[1] SMOTER (Synthetic Minority Over-sampling Technique for Regression, 회귀를 위한 합성 소수 오버샘플링 기술)
SMOTER는 잘 알려진 SMOTE 알고리즘의 회귀를 위한 적응입니다.
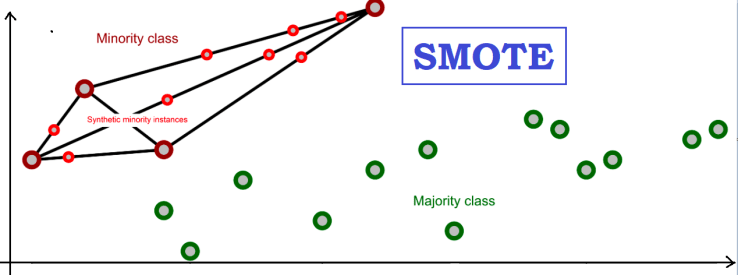
이 방법은 원래 레이블 밀도를 사용하여 자주 발생하는 (다수) 영역과 드물게 발생하는 (소수) 영역을 정의한 다음,
사용자가 SMOTER 알고리즘에 의해 수행될 오버샘플링과 언더샘플링의 비율을 사전에 결정해야 하는 곳에서 다수 영역에 랜덤 언더샘플링을 적용하고 소수 영역에 오버샘플링을 적용함으로써 작동합니다.
오버샘플링을 할 때 소수의 영역에 대해서는 새로운 합성 예제를 생성할 뿐만 아니라 다양한 예제의 입력과 목표를 결합하는 보간 전략도 적용합니다. 정확하게 말하면, 보간은 하나의 시드 케이스와 시드의 k-최근접 이웃(neighbors)에서 무작위로 선택된 두 희귀 케이스를 사용하여 수행됩니다.
- 두 케이스의 featrue(X)는 보간으로 계산
- 새로운 target 변수(Y)는 두 희귀 케이스의 목표 변수의 가중 평균으로 결정
[target 변수(Y) 평균 계산 이유]
분류 문제에 적용하는 원래 SMOTE(Synthetic Minority Over-sampling Technique)에서는 모든 희귀 케이스가 동일한 타겟 값 (레이블 or 클래스)을 가지므로 사소한 문제였음,
그러나 회귀의 경우에는 새로운 합성 케이스를 생성하기 위해 예제 쌍이 사용될 때 동일한 목표 변수 값을 가지고 있지 않을 것이기 때문에 신중한 결정이 필요함.
[2] SMOGN (Synthetic Minority Over-sampling Technique for Regression with Gaussian Noise, 가우시안 노이즈가 있는 회귀를 위한 합성 소수 오버샘플링 기술)
SMOGN은 SMOTER를 따르지만 SMOTER가 이미 가지고 있는 것과 함께 오버샘플링 단계에 가우시안 노이즈를 추가합니다.
SMOGN 알고리즘의 핵심 아이디어는 SMOTER와 가우시안 노이즈 전략을 결합하여 합성 예제를 생성함으로써, 보수적인 가우시안 노이즈 도입 전략을 사용하여 SMOTER가 초래할 수 있는 다양한 예제 부족과 같은 위험을 동시에 제한하는 것입니다. 왜냐하면 SMOTER는 보간 과정에서 가장 먼 예제를 사용하지 않기 때문입니다.
이는 시드 케이스와 선택된 k-최근접 이웃이 충분히 가까울 때만 SMOTER를 사용하여 새로운 합성 예제를 생성하고,
두 예제가 더 멀 때 가우시안 노이즈를 사용하는 방식으로 작동합니다.
[가우시안 노이즈] 가우시안 노이즈, 또는 정규 분포 노이즈는 자연 현상이나 측정 데이터에서 자주 발견되는 노이즈의 한 유형입니다. 이 노이즈는 가우스 분포 또는 정규 분포로 모델링될 수 있으며, 이는 노이즈 값이 평균이 0이고 표준 편차가 1인 정규 분포를 따른다는 것을 의미함
SMOTER는 SMOTE 알고리즘을 회귀 문제에 확장하여 적용한 것이며
SMOGN은 가우시안 노이즈를 추가하여 불균형 회귀 문제를 더 잘 처리하기 위해 SMOTER를 더욱 확장한 것
1.2 언더 샘플링(Under Sampling)
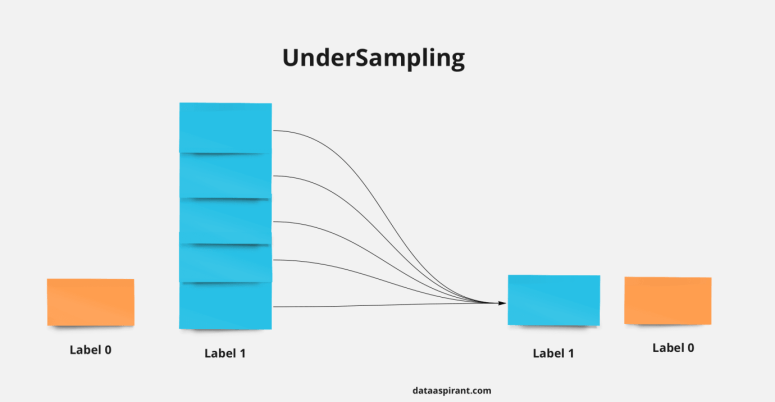
이 접근 방식에서는 소수 클래스의 샘플 수와 일치하도록 다수 클래스의 샘플 수를 줄입니다.
1) Random Sampler : 다수 클래스에서 몇 개의 샘플을 무작위로 선택하여 데이터의 균형을 맞추는 가장 쉽고 빠른 방법입니다.
2) NearMiss: 3가지 다른 휴리스틱을 구현하여 선택한 샘플에 몇 가지 상식 규칙을 추가하지만 이 문서에서는 하나만 집중적으로 설명합니다.
ex> NearMiss-2 : 가장 먼 소수 클래스 예제 3개까지의 최소 평균 거리를 갖는 다수 클래스 예제입니다.
1.3. 언더 샘플링 vs 오버 샘플링 요약
| 장점 | 단점 | |
| 오버 샘플링 |
- 기존 예제의 복사본이 아닌 합성 예제를 생성함으로써 랜덤 오버샘플링으로 인한 오버피팅을 개선 - 정보 손실 없음 - 단순함 |
- 합성 예제를 생성할 때, SMOTE는 다른 클래스에서 올 수 있는 이웃 예제를 고려하지 않습니다. 이로 인해 클래스 간의 겹침이 증가하고 추가적인 노이즈가 발생할 수 있습니다. - SMOTE는 고차원 데이터에 대해 실용적이지 않습니다. |
| 언더 샘플링 |
- 데이터셋을 균형 있게 만들고, ML 알고리즘이 대다수 클래스 쪽으로 왜곡될 위험을 줄일 수 있음 (그러나 예측 결과의 대부분이 다수 클래스 내에 속하는 경우가 많으므로 주의) - 저장소 요구 사항이 적고 분석을 위한 더 나은 실행 시간. 더 적은 데이터는 여러분 또는 여러분의 사업에 더 적은 저장소와 유용한 통찰력을 얻기 위한 시간 필요 |
- 대다수 클래스의 예를 충분히 제거하여 대다수 클래스를 소수 클래스와 동일하거나 유사한 크기로 만들면 데이터의 상당한 손실이 발생 - 선택된 대다수 클래스의 샘플이 편향될 수 있으며, 이는 실제 세계를 정확하게 대표하지 않을 수 있으며 분석 결과가 부정확할 수 있음을 의미합니다. 따라서 이는 분류기가 실제로 보이지 않는 데이터에 대해 제대로 작동하지 않을 수 있음 |
2. Algorithm approach
알고리즘 접근 방식은 다수 그룹에 대한 편견을 완화하기 위해 기존 모델을 수정하는 데 중점을 둡니다. 이를 위해서는 수정된 학습 알고리즘에 대한 좋은 통찰력과 편향된 분포 표현 학습에 실패한 이유를 정확하게 식별해야 합니다.
가장 널리 사용되는 기술은 비용에 민감한 접근 방식(가중 학습자)입니다. 여기에서 주어진 모델은 고려된 각 사례 그룹에 대해 다양한 페널티를 통합하도록 수정되었습니다. 즉, 비용 함수에서 소수 클래스에 더 높은 가중치를 할당하는 초점 손실을 사용합니다. 이는 소수 클래스를 잘못 분류한 모델에 불이익을 주는 동시에 다수 클래스의 가중치를 줄여 모델이 비용을 지불하도록 합니다. 소외 계층에 더 많은 관심을 기울이십시오. 따라서 학습 과정에서 중요성이 높아집니다.
또 다른 흥미로운 알고리즘 수준 솔루션은 대상 그룹에 초점을 맞춘 단일 클래스 학습 또는 단일 클래스 분류(OCC)를 적용하여 데이터 설명을 생성하는 것입니다. 이런 식으로 우리는 단일 개체 세트에만 집중하므로 모든 그룹에 대한 편견을 제거합니다.
OCC는 이상치 및 변칙 검색을 위한 기술을 제공하므로 불균형 분류 문제에 유용할 수 있습니다. 이는 다수 클래스 데이터(양성 예라고도 함)에 모델을 맞추고 새 데이터가 다수 클래스에 속하는지 또는 소수 클래스(음성 예라고도 함)에 속하는지 예측하여 이상값/이상 항목임을 의미합니다.
OCC 문제는 일반적으로 다수 클래스 데이터는 쉽게 사용할 수 있지만 소수 클래스는 어렵고 비용이 많이 들며 심지어 수집이 불가능한 실용적인 분류 작업입니다(예: 엔진 작업, 사기 거래, 컴퓨터 시스템에 대한 침입 감지 등).
3. Hybrid approach
하이브리드화는 개별 구성 요소의 장점을 활용하는 접근 방식입니다. 불균형한 분류 데이터를 처리할 때 일부 연구에서는 샘플링과 비용에 민감한 학습의 혼합을 제안했습니다. 즉, 데이터와 알고리즘 수준 접근 방식을 결합합니다. 데이터 수준 솔루션과 알고리즘 수준 솔루션(예: 분류자 앙상블)을 병합하여 강력하고 효율적인 학습자를 생성하는 2단계 교육 아이디어는 매우 인기가 있습니다.
- 데이터 수준 접근 방식 적용 : 데이터 수준 접근 방식은 오버샘플링이나 과소샘플링을 사용하여 다수 클래스와 소수 클래스 간의 클래스 분포의 균형을 맞추기 위해 훈련 세트를 수정하는 방식
- 분류기 앙상블 학습 (from 균형 잡힌 클래스 분포를 갖는 사전 처리된 데이터) : 즉, 앙상블 모델을 구성하는 각 구성 요소 분류기보다 더 나은 성능을 발휘하는 새로운 분류기가 파생되는 앙상블 모델을 트레이닝 함. 따라서 데이터 및 알고리즘 수준 접근 방식의 장점은 반영하고, 약점을 줄이는 강력하고 효율적인 모델 개발
참고 문헌
SMOGN
[➍] http://proceedings.mlr.press/v74/branco17a/branco17a.pdf
[➎] https://pypi.org/project/smogn/
smogn
A Python implementation of Synthetic Minority Over-Sampling Technique for Regression with Gaussian Noise (SMOGN)
pypi.org
[➐] https://rdrr.io/github/paobranco/UBL/man/SMOGNRegress.html
SMOGNRegress: SMOGN algorithm for imbalanced regression problems in paobranco/UBL: An Implementation of Re-Sampling Approaches t
This function handles imbalanced regression problems using the SMOGN method. Namely, it can generate a new data set containing synthetic examples that addresses the problem of imbalanced domains. The new examples are obtained either using SmoteR method or
rdrr.io
그 외
Regression for Imbalanced Data with Application | by Hanan Ahmed | Towards Data Science
Regression for Imbalanced Data with Application
Introduction and motivation
towardsdatascience.com
https://neptune.ai/blog/how-to-deal-with-imbalanced-classification-and-regression-data
How to Deal With Imbalanced Classification and Regression Data
Learn techniques for handling imbalanced classification and regression data with a guide for ML practitioners.
neptune.ai
http://proceedings.mlr.press/v74/branco17a/branco17a.pdf
https://github.com/nickkunz/smogn
GitHub - nickkunz/smogn: Synthetic Minority Over-Sampling Technique for Regression
Synthetic Minority Over-Sampling Technique for Regression - GitHub - nickkunz/smogn: Synthetic Minority Over-Sampling Technique for Regression
github.com
[2102.09554] Delving into Deep Imbalanced Regression (arxiv.org)
Delving into Deep Imbalanced Regression
Real-world data often exhibit imbalanced distributions, where certain target values have significantly fewer observations. Existing techniques for dealing with imbalanced data focus on targets with categorical indices, i.e., different classes. However, man
arxiv.org
Strategies and Tactics for Regression on Imbalanced Data | by Yuzhe Yang | Towards Data Science
Strategies and Tactics for Regression on Imbalanced Data
Let me introduce to you our latest work, which has been accepted by ICML 2021 as a Long oral presentation: Delving into Deep Imbalanced Regression. Under the classic problem of data imbalance, this…
towardsdatascience.com
https://github.com/YyzHarry/imbalanced-regression
A boosting resampling method for regression based on a conditional variational autoencoder - ScienceDirect
A boosting resampling method for regression based on a conditional variational autoencoder
Resampling is the most commonly used method for dealing with imbalanced data, in addition to modifying the algorithm mechanism, it can, for example, g…
www.sciencedirect.com