[번역] 모든 데이터 과학자가 시각화 툴킷에 추가해야 하는 8가지 대안
안녕하세요!
먼저, 이 글은 다음 링크의 글을 참고하여 작성되었습니다. 자세한 내용은 아래 링크를 참고해주세요.
출처 : https://open.substack.com/pub/avichawla/p/8-classic-alternatives-to-traditional?r=2vemqb&utm_campaign=post&utm_medium=email
8 Classic Alternatives to Traditional Plots That Every Data Scientist Must Add in Their Visualisation Toolkit
A consolidated guide on best plotting ideas discussed here.
www.blog.dailydoseofds.com
산점도, 막대 그래프, 선 그림, 상자 그림, 히트맵은 데이터 시각화에 가장 자주 사용되는 그림입니다.
간단하고 거의 모든 사람에게 알려져 있지만 가능한 모든 시나리오를 포괄하는 올바른 선택은 아니라고 생각합니다.
그러므로 오늘은 이러한 인기 있는 플롯에 대한 몇 가지 대안을 논의해 보고, 또한 표준 플롯보다 더 유용할 수 있는 특정 상황에 대해서도 설명하겠습니다.
이 포스팅에서 살펴 보고자 하는 시각화 기법은 다음 8가지입니다.
| 번호 | 이름 | 목적 |
| 1 | 크기 인코딩 히트맵 | 변수 간 상관관계 파악, 원의 크기나 색상을 기반으로 변수간 상관관계를 빠르게 파악 |
| 2 | 폭포형 차트 | 시간에 따른 값의 변화 시각화 : 점진적인 변화의 규모와 방향을 시각적으로 추정 |
| 3 | 범프 차트 | 시간에 따른 범주형 값의 변화 시각화(연도별 순위) |
| 4 | 레인클라우드 플롯 | 그룹별(범주형 변수)로 수치형 변수의 분포를 파악하기 위해 사용되는 Box plot, Strip plot, KDE plot을 단일 플랏으로 합쳐 한눈에 분포를 살펴보고자 함 |
| 5 | Hexbin | 2차원 평면에서 2개 변수간의 관계를 파악할 때 겹치는 점으로 인한 해석의 어려움을 해결, 육각형 영역의 색상(hexbin) 혹은 등고선을 통해 데이터 밀도 파악 |
| 6 | 밀도 도표 | |
| 7 | 버블 차트 | 막대 그래프 대신 많은 범주의 값 시각화(버블의 크기) 혹은 도트의 위치(높이) 이용 |
| 8 | 도트 플롯 |
0. Data set Load
이번 포스팅에서는 주로 iris 데이터셋을 사용하려해요.
먼저 사용할 데이터셋을 불러와줍니다.
import pandas as pd
from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load the Iris dataset
iris = datasets.load_iris()
# Create a DataFrame with column names
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# Add a 'target' column with the target labels
df['target'] = iris.target
# Add a 'target_names' column with the target class names
df['target_names'] = df['target'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})
# Assuming iris_df is your DataFrame
trimmed_column_names = [name.replace(' (cm)', '').replace(' ', '_') for name in df.columns]
df.columns = trimmed_column_names
# Print the first few rows of the DataFrame
(df.head())
iris_df = df.drop('target', 1)
iris_df

1. 크기 인코딩 히트맵
전통적인 히트맵은 색상 척도를 사용하여 값을 나타냅니다. 그러나 셀 색상을 정확한 숫자로 매핑하는 것은 여전히 어렵습니다.
이러한 경우 히트맵에 크기 구성요소를 포함하는 것이 매우 도움이 될 수 있습니다.
본질적으로 크기가 클수록 절대값이 높아집니다.

이는 0에 가까운 많은 값이 즉시 줄어들기 때문에 히트맵을 더 깔끔하게 만드는 데 특히 유용합니다.
예시
sns.set_theme(style="whitegrid")
corr_matrix = iris_df.corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=False, cmap='coolwarm')
plt.title('Correlation Heatmap (w/o coef)')
plt.show()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap (w coef)')
plt.show()


# import pandas as pd
# import numpy as np
# import seaborn as sns
# import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid") # whitegrid
# Assuming iris_df is your DataFrame
corr_matrix = iris_df.corr()
# Convert the correlation matrix to long-form
corr_df = corr_matrix.stack().reset_index()
corr_df.columns = ['variable1', 'variable2', 'correlation']
# Add a column for the absolute correlation
corr_df['abs_correlation'] = corr_df['correlation'].abs()
# Create the relplot
plot = sns.relplot(
data=corr_df,
x='variable1', y='variable2',
hue='correlation', # Color by correlation value
size='abs_correlation', # Size by absolute correlation value
palette='coolwarm', # Choose a diverging palette
sizes=(40, 600), # Control the range of sizes
# scatter_kws={'edgecolor': 'grey'} # Add grey border lines to circles
)
# Set the aspect ratio for better readability
plot.fig.set_size_inches(8, 5)
# Show the plot
plt.show()

2. 폭포형 차트
시간에 따른 값의 변화를 시각화하려면 선(또는 막대) 도표가 항상 적절한 선택이 아닐 수도 있습니다.
이는 선 도표(또는 막대 도표)가 차트의 실제 값을 표시하기 때문입니다.
따라서 점진적인 변화의 규모와 방향은 시각적으로 추정하기가 어렵습니다. 대신 폭포형 차트를 사용할 수 있습니다.
폭포형 차트는 아래 그림과 같이 이러한 롤링 차이를 우아하게 묘사합니다.

여기서 시작값과 최종값은 첫 번째 막대와 마지막 막대로 표시됩니다.
또한 연속된 변경 사항은 자동으로 색상으로 구분되어 해석하기가 더 쉽습니다.
예시
warterfall_chart 라이브러리가 설치되어 있지 않을 경우 아래 코드를 실행시켜 먼저 설치해 줍니다.
!pip install waterfallcharts
설치가 잘 되었다면 아래와 같이 차트를 그려볼 수 있습니다.
import waterfall_chart
a = ['sales','returns','credit fees','rebates','late charges','shipping']
b = [10,-30,-7.5,-25,95,-7]
my_plot = waterfall_chart.plot(a, b)

참고 : https://github.com/chrispaulca/waterfall
GitHub - chrispaulca/waterfall: An easy to use waterfall chart function for Python
An easy to use waterfall chart function for Python - GitHub - chrispaulca/waterfall: An easy to use waterfall chart function for Python
github.com
3. 범프 차트
여러 범주의 시간에 따른 순위 변화를 시각화할 때 막대 차트를 사용하는 것은 적절하지 않을 수 있습니다. 이는 막대형 차트가 많은 범주로 인해 빠르게 복잡해지기 때문입니다.
대신 범프 차트(Bump Charts)를 사용해 보세요 . 특히 시간 경과에 따른 다양한 항목의 순위를 시각화하는 데 사용됩니다.
범프차트란?
범프 차트는 시간에 따른 순위나 위치의 변화를 표시하는 데 사용되는 데이터 시각화 유형입니다. 다양한 기간에 걸쳐 순위 순서에 따라 다양한 엔터티의 상승 및 하락을 표시하는 데 특히 유용합니다. 범프 차트는 경쟁 결과, 주식 순위, 판매 수치 또는 시간 경과에 따른 기타 유형의 순위 데이터를 시각화하는 데 유용합니다.

위의 막대 차트와 범프 차트를 비교해 보면, 막대 차트보다는 범프 차트를 사용하는 것이 순위 변화를 해석하기 훨씬 쉽습니다.
범프차트 그리기 참고 : https://github.com/ChawlaAvi/Daily-Dose-of-Data-Science/blob/main/Plotting/Bump-chart.ipynb
범프 차트를 직접 그려보자면 다음과 같이 그릴수 있겠는데요.
아래 그림에서와 같이 동일한 내용의 시각화 결과이지만, 막대그래프에 비해서 훨~씬 더 연도별 팀의 순위 변화 추이를 범프 차트를 통해 훨씬 더 잘 파악할 수 있다는 점 잊지 마세요!
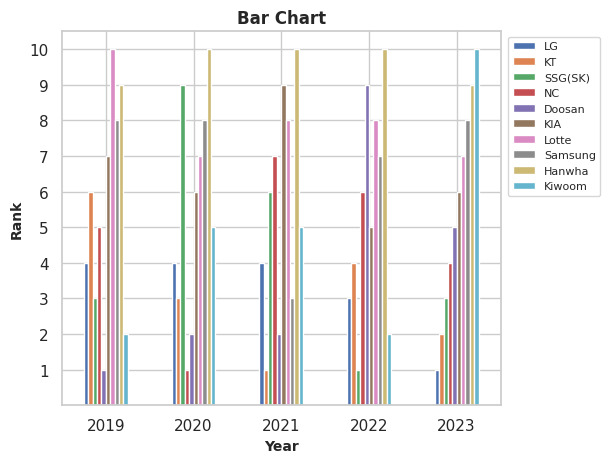

예시
# 가정된 데이터프레임 예시
data = {
"2019": ['Doosan','Kiwoom','SSG(SK)','LG','NC', 'KT', 'KIA', 'Samsung', 'Hanwha','Lotte'],
"2020": ['NC','Doosan','KT','LG','Kiwoom','KIA','Lotte','Samsung','SSG(SK)','Hanwha'],
"2021": ['KT','Doosan','Samsung','LG','Kiwoom','SSG(SK)','NC','Lotte','KIA','Hanwha'],
"2022": ['SSG(SK)','Kiwoom','LG','KT','KIA','NC','Samsung','Lotte','Doosan','Hanwha'],
"2023": ['LG','KT','SSG(SK)','NC','Doosan','KIA','Lotte','Samsung','Hanwha','Kiwoom'],
}
df = pd.DataFrame(data)
df
team_lst = data['2023']
df2 = pd.DataFrame(index = team_lst)
print(df2)
for yr in data.keys():
tmp_lst = []
for i in team_lst:
tmp_lst = tmp_lst + [data[yr].index(i) + 1]
print(yr, tmp_lst)
df2[yr] = tmp_lst
df = df2.T
df = df.reset_index()
df.columns = ['Year'] + team_lst
## Bar chart
sns.set_theme(style="whitegrid")
fig, ax = plt.subplots()
fig=df.plot(x='Year', kind='bar', stacked=False, ax = ax);
ax.set_xlabel('Year', fontsize = 10, fontweight="bold")
ax.set_ylabel('Rank', fontsize = 10, fontweight="bold")
ax.set_title('Bar Chart', fontsize = 12, fontweight="bold")
ax.set_xticklabels(df.Year, rotation = 0)
# Inverting the y-axis & Set y-axis ticks
plt.yticks(range(1, 11))
# Adding a legend & Setting layout tight
plt.legend(loc='upper right', bbox_to_anchor=(1.24, 1), fontsize=8)
plt.tight_layout()
plt.show();
## Bump chart
# Define a list of colors
colors_dict = {'Doosan': 'navy','Kiwoom': 'magenta','SSG(SK)': 'green','LG': 'black',
'NC': 'gold', 'KT': 'aquamarine', 'KIA': 'red', 'Samsung': 'royalblue', 'Hanwha': 'orange','Lotte': 'darkred'
}
sns.set_theme(style="white")
# Create the bump chart
for team in df2.index:
plt.plot(df2.columns, df2.loc[team], marker='o', label=team, # color=colors_dict[team]
)
# Inverting the y-axis & Set y-axis ticks
plt.gca().invert_yaxis()
plt.yticks(range(1, 11))
# Adding labels and title
plt.xlabel('Year')
plt.ylabel('Rank')
plt.title('KBO Team Ranks Over Years[2019-2023]', fontweight="bold")
# Adding a legend & Setting layout tight
plt.legend(loc='upper right', bbox_to_anchor=(1.3, 1), fontsize=9)
plt.tight_layout()
# Show the plot
plt.show()
4. Raincloud(레인클라우드) 플롯
이 포스트에서 가장 추천하고 싶은 플랏은 바로 이 플랏입니다! 데이터 분포를 한눈에 보기에 정말 좋은 시각화 도구인것 같아요!
레인 클라우드 플롯이 무엇인지 간단하게 알아보겠습니다.
"레인 클라우드 플롯"은 통계 및 데이터 분석에서 사용되는 데이터 시각화 유형으로, 박스 플롯과 커널 밀도 플롯의 요소를 결합한 것입니다. 이 플롯은 데이터 분포에 대한 보다 포괄적인 시각을 제공하는 것을 목표로 합니다. 일반적으로 다음과 같이 작동합니다:
1. 커널 밀도 플롯(KDE) : 이것은 플롯의 '구름' 부분입니다. 데이터의 확률 밀도를 보여주어 데이터 포인트가 가장 밀집된 곳을 알 수 있게 합니다.
2. 박스 플롯 또는 점 플롯 : 밀도 플롯 아래에는 종종 박스 플롯이나 개별 데이터 포인트의 시리즈(Strip plot, 점 플롯)가 있습니다. 이 레인 클라우드 플롯의 측면은 중앙값, 사분위수, 이상치와 같은 데이터에 대한 전통적인 통계 정보를 제공합니다.
3. 레이아웃과 미학 : 이러한 요소들을 하나의 플롯에서 결합함으로써 데이터 분포에 대한 더욱 심도 깊은 이해를 할 수 있습니다. '비'에 비유되는 것은 데이터 포인트가 밀도 플롯의 '구름'에서 '떨어지는' 것처럼 보이는 방식에서 비롯됩니다.
레인 클라우드 플롯은 많은 정보를 시각적으로 매력적이고 쉽게 해석할 수 있는 방식으로 전달할 수 있기 때문에 특히 가치가 있습니다. 이는 그룹 간 분포를 비교하는 데 유용하며, 심리학과 생의학 과학 분야에서 인기가 있습니다.
레인클라우드 플롯을 구성하는 요소 중 Strip plot과 KDE plot에 대해 조금 더 알아보자면

- Strip Plot
- 정의 및 사용
- Strip Plot은 데이터의 분포를 나타내는 간단한 형태의 플롯입니다. 일반적으로 범주형 축을 가진 scatter plot으로 생각할 수 있습니다.
- 이 플롯은 데이터 포인트를 그대로 표시하여, 각 데이터 항목의 실제 값을 시각적으로 나타냅니다.
Strip Plot은 데이터 포인트들이 겹치는 경우가 많기 때문에 주로 작은 데이터셋이나 개별 관측치를 강조할 때 유용합니다.
- 주요 특징
- 데이터의 분산이나 밀집도를 한눈에 파악하기 쉽습니다.
- 데이터 포인트 간의 겹침을 피하기 위해 'jitter' 옵션을 사용할 수 있으며, 이는 포인트들을 약간씩 수평으로 분산시켜 겹침을 줄입니다.
- 다양한 범주형 변수를 나란히 표시하여 비교하기 좋습니다.
- 정의 및 사용
- KDE Plot (Kernel Density Estimation Plot)
- 정의 및 사용
- KDE Plot은 연속적인 확률 밀도 곡선을 그리는 방법으로, 데이터의 분포를 시각화합니다.
- 이 방법은 각 데이터 포인트 주변에 '커널'(보통 가우시안)을 두어 데이터 분포를 부드럽게 추정합니다.
- KDE는 데이터셋의 밀도 추정이 중요할 때 사용되며, 히스토그램보다 부드러운 분포 곡선을 제공합니다.
- 주요 특징:
- 데이터 분포의 형태를 연속적이고 부드러운 곡선으로 나타냅니다.
- 이상치의 영향을 덜 받으면서도 전체 데이터의 특성을 잘 나타내줍니다.
- 밴드폭(Bandwidth) 매개변수를 조정하여, 곡선의 부드러움 정도를 조절할 수 있습니다. 밴드폭이 크면 더 부드러운 곡선을, 작으면 더 뾰족한 곡선을 만듭니다.
- 정의 및 사용
상자 그림과 히스토그램을 사용하여 데이터 분포를 시각화하는 것은 때때로 오해의 소지가 있을 수 있습니다. 이유:
- 완전히 다른 데이터로 동일한 상자 그림을 얻는 것이 가능합니다.
- 빈 수를 변경하면 히스토그램의 모양이 변경됩니다.
따라서 오해의 소지가 있는 결론을 피하기 위해 항상 데이터 분포를 가능한 한 정확하게 표시하는 것이 좋습니다.
Raincloud 플롯은 세 가지 유형의 플롯을 함께 결합하고 시각화하는 간결한 방법을 제공합니다.
여기에는 다음이 포함됩니다.
- 데이터 통계를 위한 상자 그림.
- 데이터 개요를 위한 스트립 플롯.
- KDE는 데이터의 확률 분포를 표시합니다.

Raincloud 플롯을 사용하면 다음을 수행할 수 있습니다.
- 부정확하거나 오해의 소지가 있는 결론을 방지하기 위해 여러 플롯을 결합합니다.
- 혼란을 줄이고 명확성을 향상
- 그룹 간 비교 개선
- 단일 플롯을 통해 데이터의 다양한 측면 파악 가능
예시
먼저 레인클라우드 플롯을 그리기 위해 필요한 라이브러리를 설치해 줍니다.
!pip install ptitprince
import ptitprince as pt
sns.set_theme(style="whitegrid")
plt.rcParams['figure.dpi'] = 100
pt.RainCloud(data = iris_df, x = 'target_names', y = 'sepal_length', orient = 'h')
plt.show()
pt.RainCloud(data = iris_df, x = 'target_names', y = 'sepal_length', orient = 'v')
plt.show()


5-6. Hexbin 및 밀도 도표
수천 개의 데이터 포인트가 있으면 점이 많이 찍혀서 밀도가 높은 영역에서 산점도가 너무 조밀해 해석할 수 없습니다.
(5) Hexbin
이러한 산점도는 Hexbin 도표로 대체할 수 있습니다.
Hexbin은 차트 영역을 육각형 영역으로 분류합니다. 각 영역에는 사용된 집계 방법(예: 포인트 수)을 기반으로 색상의 진하기(강도)가 할당됩니다.

(6) Density Plot
또 다른 선택은 2차원 공간에서 점의 분포를 보여주는 밀도 플롯입니다.

밀도 플롯(Density plot)에서는 밀도가 같은 점을 연결하여 윤곽선(등고선)을 만듭니다. 즉, 단일 등고선은 동일한 밀도의 데이터 포인트를 나타냅니다.
7-8. 버블 차트와 도트 플롯
위에서 설명한 대로 막대 그래프는 범주 수가 증가함에 따라 빠르게 지저분해지고 복잡해집니다.
이러한 경우 버블 플롯이 더 나은 대안이 되는 경우가 많습니다.
이는 산점도와 비슷하지만 다음과 같습니다.
- 하나의 범주형 축 포함
- 하나의 연속 축

위와 같이
- 막대 그래프 : 작은 공간에 막대가 너무 많이 들어있어 해석 어려움
- 버블차트 : 크기가 인코딩된 버블(거품) 사용 시 시간 경과에 따른 변화 시각화 매우 쉬움
이러한 상황에서 막대 그래프의 또 다른 대안은 도트 플롯입니다.

도트 플롯과 버블 차트는 막대가 많은 막대 플롯이 있을 때 개별 막대 길이에 주의를 기울이지 않는 경우가 많기 때문에 유용합니다.
막대 대신 우리는 값의 크기(수치)를 나타내는 각 데이터 별 끝점(최상단)을 주로 고려합니다. 이러한 플롯은 이를 정확하게 묘사하는 데 도움이 되는 동시에 거의 사용되지 않는 긴 막대(아랫부분)를 제거합니다.