728x90
반응형
출처 : 2023년의 딥러닝과 LLM 생태계 (sk.com)
2023년의 딥러닝과 LLM 생태계
33차 Tech 세미나 진행합니다. 이번 Tech 세미나는 “2023년의 딥러닝과 LLM 생태계”에 대해 준비하였습니다. 2018년 트랜스포머 이후 시퀀스 예측 기반의 딥 러닝 모델은 엄청난 발전을 이루었
devocean.sk.com
[Agenda]
1. 2023년 거대 언어 모델의 대두
2. 거대 언어 모델 기반의 응용 사례
3. 거대 언어 모델 기반 서비스의 난제
4. 2023년 초, 중순의 변화의 시사점과 향후 방향
[발표자] 신정규
현) 래블업 주식회사 대표 - Google Developer Experts (ML분야), Google For Startup Accelerator Mentor - SW산업발전유공 대통령표창
내용 정리
- 생성형 AI : 컨텐츠를 '생성' 해 내는 능력?, 결과물을 만들어내는?
- 생성 AI의 종류 : 다 달라보이지만 근본적으로는 같은 모델
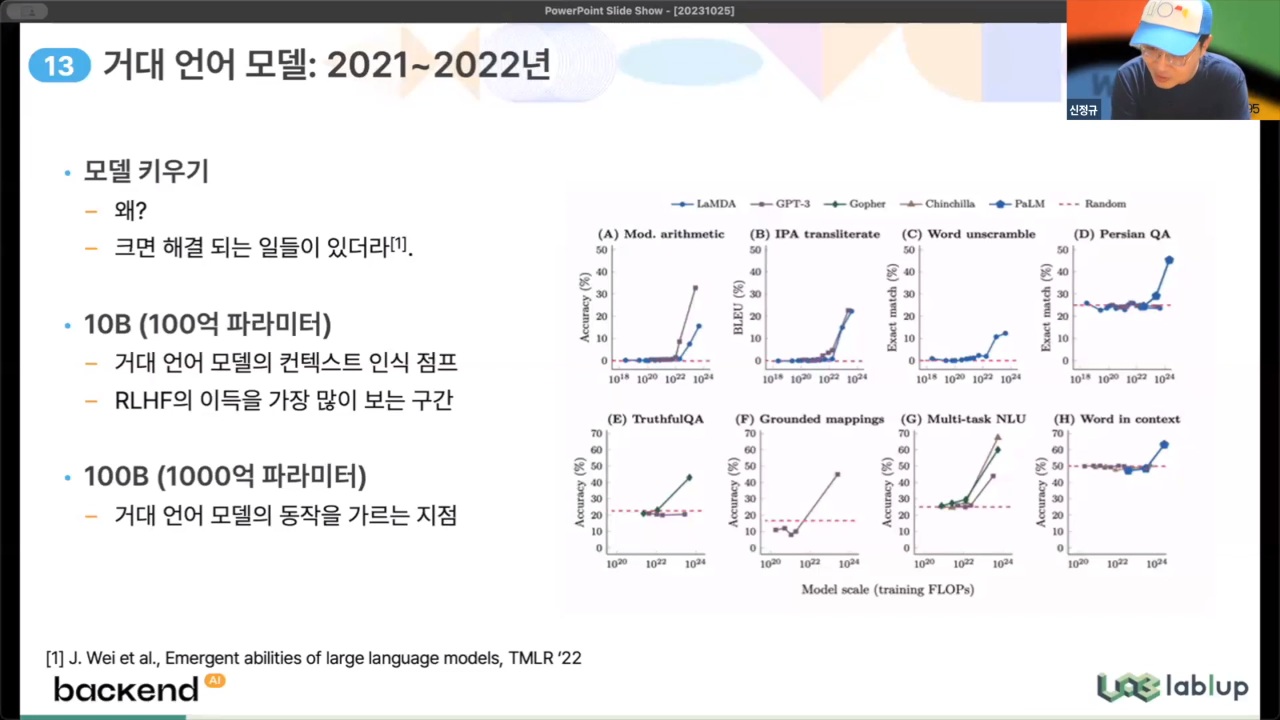
- 거대 언어 모델 : 선형적이 아닌 지수적으로 폭발적으로 증가 [18' 트랜스포머 → 20' 거대 언어모델의 특이점 발견 → 22' chatGPT 이후 계속 진화중
- 이미지 생성 모델
- 멀티모달
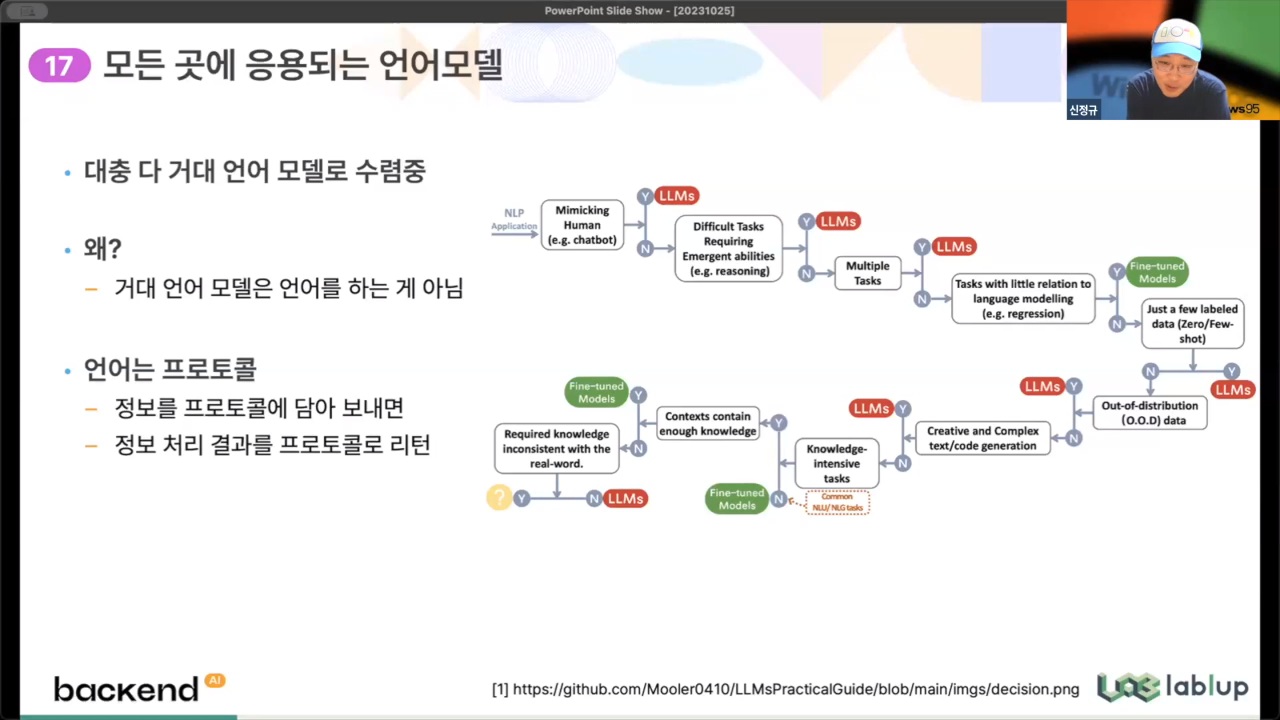
- 거대 언어 모델로 수렴 중 : 거대 언어모델은 언어를 하는 것이 아님, 정보를 프로토콜에 담아 보내면 결과를 프로토콜로 리턴하는 구조로 이루어져 있음
- LLM은 챗봇이 아님, 챗봇은 실제 대화를 하는 것이 아님 : 글을 계속 이어쓰는 형태, '질문-대답'의 반복이 그 다음 질문의 입력으로 사용
- 프롬프트 : 글의 중간을 채워 넣는 방법 (마치 수능 외국어/영어 영역의 빈칸 추론 문제와 같은 원리!)
 2020학년도 수능 영어 34번 문제
2020학년도 수능 영어 34번 문제
- 프롬프트 : 글의 중간을 채워 넣는 방법 (마치 수능 외국어/영어 영역의 빈칸 추론 문제와 같은 원리!)
- 파인튜닝 : 기반 모델을 만드는데는 엄청난 자원이 소모됨(~수천억원), 따라서 서비스 용 모델은 기반 모델을 개발해 두고 이를 바탕으로 각 용도에 맞게 미세 조정하여 개발
ex> 구글 Pathways(기반 모델) ~ PaLM, Med-PaLM, Sec-PaLM, 미네르바(세부 모델) - GPU/NPU 하드웨어 시장 용어 설명
| 하드웨어 장치 | 설명 |
| GPU (Graphic Processing Unit) |
- 딥러닝 계산을 가속화하기 위한 장치(원래는 게임용으로 많이 사용) - 수천 개의 산술논리연산유닛(ALU)이 탑재돼 량의 연산을 동시에 수행하는 처리가 CPU에 비해 압도적으로 빠른 기계학습 가능 - GPU는 게임이나 CG 처리 등에도 활용할 수 있는 범용 칩이기 때문에 머신러닝 전용 설계 칩에 비해 효율 떨어짐 |
| NPU (Neural (network) Processing Unit) |
- AI 반도체, 딥러닝 계산을 가속화하기 위해 만듦 - GPU와 마찬가지로 대량의 연산을 동시에 수행하는 처리에 특화 - 머신러닝 전용으로 설계된 칩이기 때문에 GPU보다 더 효율적으로 연산 수행 - 머신러닝 전용 설계 칩 : CPU나 GPU처럼 다양한 용도로 사용할 수 없음 |
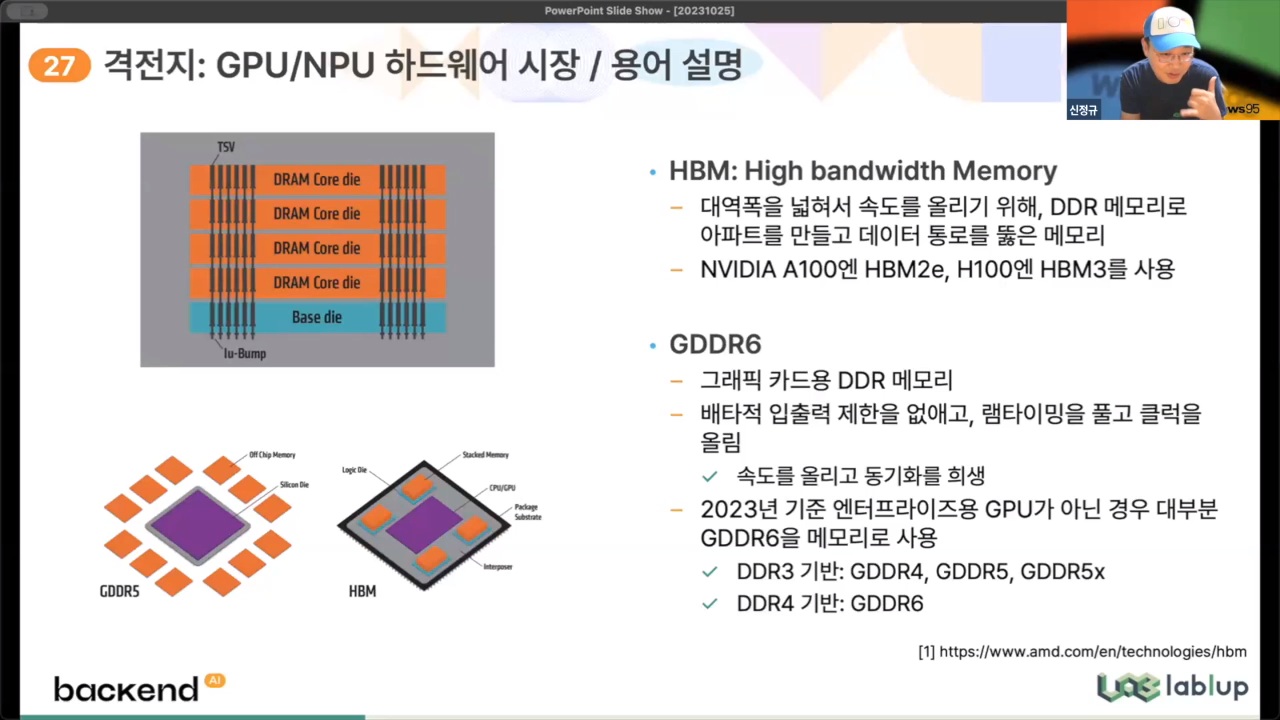
| HBM (High Bandwidth Memory) |
- 대역폭을 넓혀서 속도를 올리기 위해 DDR 메모리로 아파트를 만들고 데이터 통로를 뚫음 (여러 개의 D램을 수직 연결해 기존 D램보다 데이터 처리 속도를 혁신적으로 개선) |
| GDDR6 | - 그래픽 카드용 DDR 메모리 - 속도를 올리고 동기화를 희생 |

















[참고] TPU란?
TPU는 ‘Tensor Processing Unit’의 약자로 구글이 개발한 NPU의 일종이다. 구글은 클라우드 컴퓨팅 서비스 ‘Google Cloud’를 통해 사용자에게 TPU의 처리 능력을 제공하고 있다. 사용자는 스스로 하드웨어를 준비하지 않아도 머신러닝 관련 처리를 고효율로 수행할 수 있다.
구글은 자사가 제공하는 ‘TPU v4’가 엔비디아의 머신러닝 관련 처리 특화 GPU ‘A100’보다 1.2~1.7배 빠르고, 전력 효율도 1.3~1.9배 우수하다고 주장하고 있다.
출처 : CPU•GPU•NPU•TPU의 차이 < ICT < 기사본문 - 테크튜브 (techtube.co.kr)
CPU•GPU•NPU•TPU의 차이 - 테크튜브
인공지능(AI) 개발에 필수적인 머신러닝에는 GPU, NPU, TPU 등의 프로세싱 칩이 사용되고 있는데, 각각의 차이점을 알기 쉽지 않다. 구글과 클라우드 스토리지 서비스를 제공하는 ‘Backblaze’가 CPU, G
www.techtube.co.kr
반응형
'IT' 카테고리의 다른 글
| 키보드 스위치/키캡 보관용 다이소 꿀템 추천(말랑한 뚜껑 저장용기) (0) | 2026.01.30 |
|---|---|
| [macOS] 맥북에서 여러 사진 넘겨가면서 보기(a.k.a. 미리보기) (0) | 2024.03.19 |
| [macOS] 맥북 유용하게 쓰는 앱&초기 설정 정리(꿀팁 대방출) (0) | 2024.02.01 |
| [갤럭시] 키보드 특수기호 배치 바꾸기(+스페이스바 크기 늘이기) (0) | 2022.04.01 |



