분류 문제의 정의와 종류
많은 머신러닝(기계학습) 문제는 분류에 해당합니다.
분류 문제는 입력 데이터가 주어졌을 때 이산 범주(discrite category)를 예측하는 작업입니다.
분류를 수행하는 분류기는 예측하고자 하는 범주의 수에 따라 이진 분류와 다중 분류로 나눌 수 있습니다.
- 이진 분류(binary classification) : 휴대전화 카메라 앞에 있는 항목이 핫도그인지 아닌지 여부(yes or no) 결정
- 다중 클래스 분류(multi-class classification) : Amazon 패키지가 일찍, 늦게 또는 정시에 도착할지 예측(2개 이상의 카테고리를 예측하는 것)
Confusion Matrix (혼동 행렬)
분류 모델 평가지표(metric)의 중요성을 확인하는 데 도움이 되도록 분류 모델의 성능을 시각화하는 간단한 기술인 혼동 행렬을 사용합니다.
일반적으로는 Confusion Matrix 라는 말을 혼동행렬이라는 용어보다 많이 사용합니다.
Counfusion Martix의 각 칸에는 실제와 예측 결과 나타날 수 있는 모든 조합(이진 분류의 경우 2*2 = 총 4가지)을 나열하고, 각 케이스에 해당하는 데이터 갯수를 기입합니다.
| Predicted : 1 (예측 : 1) | Predicted : 0 (예측 : 0) | |
| Actual : 1 (실제 : 1) | True Positive (TP) | False Negative (FN) [2종 오류(β)] |
| Actual : 0 (실제 : 0) | False Positive (FP) [1종 오류 (α)] |
True Negative (TN) |
* 1종 오류 (음성->양성)
귀무가설이 실제 참이지만, 귀무가설을 기각하는 오류. 즉, 실제 음성인 것을 양성으로 판정하는 경우.
거짓 양성 또는 알파 오류(영어: α error)라고도 한다.
* 2종 오류 (양성->음성)
귀무가설이 실제 거짓이지만, 귀무가설을 채택하는 오류. 즉, 실제 양성인 것을 음성으로 판정하는 경우이다.
거짓 음성 또는 베타 오류(영어: β error)라고도 한다.
출처 : https://ko.wikipedia.org/wiki/1%EC%A2%85_%EC%98%A4%EB%A5%98%EC%99%80_2%EC%A2%85_%EC%98%A4%EB%A5%98
모델의 Raw(단순) 정확도(올바르게 할당된 범주의 수를 총 예측 수로 나눈 값)를 보는 대신, 혼동 행렬은 예측을 관심 있는 여러 범주로 분해하여 한 클래스가 다른 클래스와 어떻게 혼동될 수 있는지 명시합니다.
| True Positive (TP) | 양성으로 올바르게 분류된 양성 인스턴스의 수 | ex> 이메일이 실제로 스팸인 경우 스팸으로 예측 |
| False Positive (FP) | 양성으로 잘못 분류된 음성 인스턴스의 수 | ex> 이메일이 실제 스팸이 아닐 때 스팸이라고 예측하는 것 |
| True Negative (TN) | 부정으로 올바르게 분류된 부정 인스턴스의 수 | ex> 이메일이 스팸이 아니라고 예측했고, 스팸이 아님 |
| False Negative (FN) | 음성으로 잘못 분류된 양성 인스턴스의 수 | ex> 이메일이 실제로 스팸일 때, 스팸이 아니라고 예측 |
분류 모델 평가 지표
| 평가지표 | 산식 | 설명 | 예시 |
| 정확도 (Accuracy) |
(TP+TN) / (TP+FN+FP+TN) |
전체 결과 중 예측과 실제가 일치한 비율 | |
| 정밀도 (Precision) |
TP/(FP+TP) | 양성 예측 결과 중 정확한 예측의 비율 * 분자: 실제 Positive를 잘 판단한 경우 * 분모: 예측을 Positive로 한 모든 경우 잘못된 Positive를 줄이는 데에 초점 |
ex) 스팸메일 분류 스팸을 스팸메일로 분류하지 않는 것(FN) : 큰 문제가 없음 스팸메일 아닌 것을 스팸메일로 분류(FP) : 업무 차질 발생 FN보단 FP를 줄이는 것이 중요한 경우 |
| 재현율 (Recall) = 민감도 (Sensitivity) = 진양성률 (True Positive Rate) |
TP/(FN+TP) | 실제 양성 중 모델이 정확하게 양성으로 예측한 비율 * 분자: 실제 Positive를 잘 판단한 경우 * 분모: 실제 값이 Positive인 모든 경우 잘못된 Negative를 줄이는데 초점 |
ex) 악성코드 판별 악성코드 아닌데 악성코드로 분류(FP) : 사용자가 확인하고 예외처리 하면 됨 악성코드인데 악성코드 아닌 것으로 분류(FN) : 악성코드에 감염되어 위험 노출 FP보단 FN를 줄이는 것이 중요한 경우 |
| 특이도(Specificity) \ = 진음성률 (True Negative Rate) |
TN/(FP+TN) | 실제 음성 중 모델이 정확하게 음성으로 예측한 비율 | ex) 진단시약 특이도가 100%라는 것은 질병에 감염되지 않은 사람을 양성이라고 잘못 진단할 위양성률이 0%라는 것을 의미 |
| F1-Score | 2*((Precision*Recall) / Precision+recall) |
정밀도와 재현율의 조화평균 정밀도와 재현율이 모두 중요한 경우, 둘을 따로 볼 경우 Trade-off 관계가 발생하여 판단 어려움 |
Example
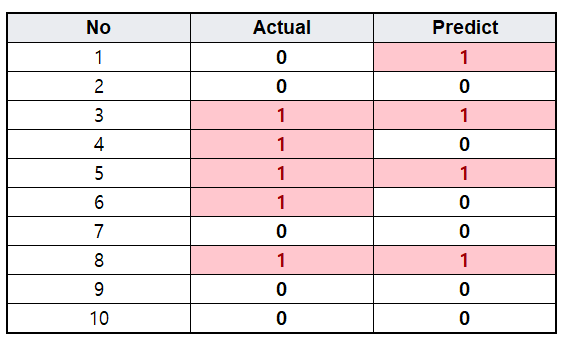
예를 들어 다음과 같이 10개의 데이터가 있을 때, 실제값과 예측값은 다음과 같습니다.
(4번 데이터를 보면 실제는 1인데 예측은 0으로 한 경우를 의미)


출처
Precision & Recall (mlu-explain.github.io)
Precision and Recall
A visual introduction to Precision, Recall, and the F1-score in machine learning.
mlu-explain.github.io
https://itwiki.kr/w/%ED%98%BC%EB%8F%99_%ED%96%89%EB%A0%AC
IT위키
IT에 관한 모든 지식. 함께 만들어가는 깨끗한 위키
itwiki.kr
'Data Analysis' 카테고리의 다른 글
| [번역] 당신은 Train, Validation & Test Set을 올바르게 사용하고 있습니까? (0) | 2023.11.28 |
|---|---|
| Over Sampling for Regression (0) | 2023.11.01 |
| [Python] Lambda 함수 사용법(for 데이터분석가) (0) | 2023.03.15 |
| PCA(주성분분석) vs LDA(선형판별분석) 비교 (0) | 2023.01.27 |
| [Python] iris dataset load & pre-processing (0) | 2022.02.10 |



