안녕하세요!
오늘은 파이썬을 사용할 때 유용한 람다 함수에 대해 설명한 글을 간단히 소개드리려 해요!
Lambda 함수는 익명 함수라고도 하며 이름 없이 정의됩니다.
이러한 함수는 완전한 함수 정의를 작성할 필요 없이 함수를 신속하게 정의해야 하는 상황에서 특히 유용합니다.
일반적인 파이썬 함수는 아래와 같이 정의됩니다. 아래 예시는 x와 y 2개 값을 입력받아 두 값을 더해주는 add라는 함수를 정의하고 사용해 본 예시예요.
def add(x, y):
return x + y
'''
add(10, 7)
17
'''
이때 반드시 함수에는 이름과 입력값, 그리고 출력값(반환값, 리턴값)이 있어야 합니다. 람다 함수를 살펴보기 전에 위의 구조를 한번 다시 기억해 주세요!
람다 함수는 익명함수라는 이름답게 이름을 정의하지 않고도 사용할 수 있어요.
람다 함수 소개 및 구조
데이터 과학 분야에서 Lambda 함수는 자주 고차 함수(higher-order functions)와 함께 사용됩니다.
이는 하나 이상의 함수를 인자로 받거나 함수를 결괏값으로 반환하는 함수입니다. 대표적인 예로는 map(), filter(), reduce() 등이 있습니다.
응용사례에 대해 살펴보기 전에, 먼저 Lambda 함수의 구문을 살펴보겠습니다.


파이썬에서 람다함수를 사용하기 위해서는 1번째 functions object를 제외한 다음 4가지 요소가 반드시 필요해요.
| Function Object | (등호 옆 좌변) | 람다 함수 실행 결과를 저장하기 위해 사용 |
| Keyword | 키워드(lambda) | 람다 함수를 정의하기 위해 약속된 키워드 'lambda' |
| Arguments | 인수 | 람다 함수는 하나 이상의 인수를 입력받을 수 있는데, 인수 여러개일 경우 콤마로 구분 |
| Colon | 콜론(:) | 인수와 표현식을 구분하기 위해 사용 |
| Expression | 표현식 | 람다 함수가 평가하고 값을 반환하기 위한 하나의(단일) 표현식 |
이 구문을 이용해서 맨 처음 살펴보았던 두 개의 인수 x, y를 입력받아 두 값의 합계를 반환하는 람다 함수의 기본 예제를 만들 수 있습니다.

람다 함수 주위에 괄호를 사용하면 함수를 즉시 정의하고 실행할 수 있는 "즉시 호출된 함수 표현식"이라는 원칙을 사용할 수 있습니다.
람다 함수는 표현식이므로 이름을 지정할 수도 있습니다. 아래 예제에서는 이전과 동일한 함수를 정의하지만 이번에는 "add2"라고 해보겠습니다.

이제 람다 함수의 구문을 더 잘 이해했으므로 람다 함수가 자주 사용되는 몇 가지 일반적인 사용 사례를 살펴보겠습니다.
데이터 과학에서의 응용
Lambda 함수는 일반적으로 하나 이상의 함수를 인수로 사용할 수 있는 고차 함수와 함께 데이터 과학에서 사용됩니다. 클로저라고 하는 중첩 함수에서도 사용할 수 있습니다.
몇 가지 구체적인 예를 살펴보겠습니다. 가능한 경우 Python list과 Pandas 데이터프레임 모두에 대한 람다 함수의 유용성을 검토할 것입니다.
1. 데이터 변환(Data Transformation)
매우 왜곡된 데이터 샘플이 있고 이를 로그 변환하여 왜곡을 줄이려고 한다고 가정합니다.
또는 해상 마일로 변환하려는 킬로미터 단위의 데이터가 있을 수 있습니다. 이러한 유형의 변환은 람다 함수를 사용하여 쉽게 수행할 수 있습니다. (1 mile=1.852km)
다음은 람다 함수를 사용하여 킬로미터를 해리로 변환하는 방법에 대한 간단한 예입니다.
list를 사용할 때는 람다 함수와 iterable(여기선 'data_km' list)을 인수로 취하는 파이썬 내장 map 함수를 사용합니다.
# list
data_km = [1, 2, 3, 4, 5]
data_nm = list(map(lambda x: x / 1.852, data_km))
'''
data_nm
[0.5399568034557235,
1.079913606911447,
1.6198704103671706,
2.159827213822894,
2.6997840172786174]
'''# Pandas DataFrame
import pandas as pd
df = pd.DataFrame({'data_km': [1, 2, 3, 4, 5]})
df['data_nm'] = df['data_km'].apply(lambda x: x / 1.852)
'''
df
data_km data_nm
0 1 0.539957
1 2 1.079914
2 3 1.619870
3 4 2.159827
4 5 2.699784
'''
2. 필터링(Flitering)
필터링은 전체 데이터 중 특정 조건을 만족하는 일부 데이터를 선택해 데이터의 특정 하위 집합(부분집합, subset)으로만 작업하려는 경우에 유용합니다.
만약에 우리에게 나이 열(칼럼, 데이터)이 포함된 의료 데이터가 있고 나이가 75세를 초과하는 노인 환자에만 관심이 있다고 가정합니다. 함수와 반복 가능 항목을 입력 인수로 사용하는 기본 제공 필터 함수를 사용하여 다음을 수행할 수 있습니다. 다음과 같이 이를 수행합니다.
# list
data_all = [84, 61, 27, 75, 90]
data_elderly = list(filter(lambda x: x > 75, data_all))
'''
data_elderly
[84, 90]
'''[참고] 사실 기본 리스트 내포 구문을 이용해서도 리스트 내에서 필요로 하는 원소를 선택할 수도 있습니다. 아래 제가 작성헀던 글과 예시를 참고해 주세요!
[Python] list comprehension 중 if else 필터링 (tistory.com)
[Python] list comprehension 중 if else 필터링
List comprehension 구문 안에 if else 문을 넣고 싶었는데, 항상 형식을 잊어먹어 여기에 정리해 두고자 합니다. 1. 문자열 리스트 [스크립트] # ============================================================================
woomii.tistory.com
# list comprehension 을 이용한 필터링 예시
data_all = [84, 61, 27, 75, 90]
data_elderly = [i for i in data_all if i > 75]
# 리스트 내의 원소를 하나씩 불러오고(i) i > 75 일 경우만 data_elderly에 저장
'''
data_elderly
[84, 90]
'''
3. 정렬(Sorting)
Lambda 함수를 사용하여 특정 기준에 따라 데이터를 정렬할 수 있습니다. 예를 들어 람다 함수를 사용하여 특정 열을 기준으로 목록 또는 데이터 프레임을 정렬할 수 있습니다.
아래 예시는 성을 기준으로 정렬하려는 names라는 list가 있습니다. 리스트 정렬은 다음과 같이 수행할 수 있습니다.
# list
names = ["James Watt", "Charles Darwin", "Carl Friedrich Gauss"]
names.sort(key=lambda x: x.split()[-1])
'''
names
['Charles Darwin', 'Carl Friedrich Gauss', 'James Watt']
'''
# Pandas DataFrame
import pandas as pd
names = ["James Watt", "Charles Darwin", "Carl Friedrich Gauss"]
df = pd.DataFrame({'names': names})
df_sorted = df.sort_values(by="names", key=lambda x: x.str.split().str[-1])
'''
df_sorted
names
1 Charles Darwin
2 Carl Friedrich Gauss
0 James Watt
'''
4. 데이터 그룹핑 및 집합 (Grouping and Aggregation)
Analyzing data at a group level can often help deriving meaningful insights into the differences between groups. Pandas data frames, along with the groupby and agg functions, are a commonly used framework for doing so.
Suppose you have some clinical data containing information on patients who took part in an experiment that was divided into three groups: A, B, and C, each containing slightly different procedures. After performing the experiments and collecting the corresponding data, you would like to take a look at the fraction of patients assigned to each experimental group:
그룹 수준에서 데이터를 분석하면 종종 그룹 간의 차이점에 대한 의미 있는 인사이트를 얻는 데 도움이 될 수 있습니다. Pandas 데이터 프레임은 groupby 및 agg 함수와 함께 이를 위해 일반적으로 사용되는 프레임워크입니다.
예를 들어, A, B, C 세 그룹으로 나누어진 실험에 참가한 환자들의 정보를 포함하는 임상 데이터가 있다고 가정해 봅시다. 실험을 수행하고 해당 데이터를 수집한 후 각 실험 그룹에 할당된 환자 비율을 살펴보고자 합니다.
import pandas as pd
group = ['A', 'B', 'A', 'A', 'B', 'C']
age = [84, 61, 27, 75, 90, 56]
weight = [164, 189, 135, 121, 172, 138]
df = pd.DataFrame({'group': group, 'age': age, 'weight': weight})
df_grouped = df.groupby('group').apply(lambda x: x['group'].count() / df.shape[0])
'''
df_grouped
group
A 0.500000
B 0.333333
C 0.166667
dtype: float64
'''
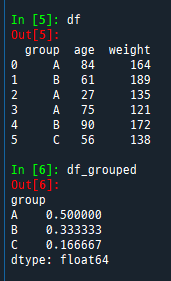
위의 분석 결과를 보면 대부분의 환자가 실험 그룹 A (50%)에 배정되었음을 알려줍니다. 그리고 B 그룹(33.33%)과 C 그룹(16.67%)이 그 뒤를 이었습니다.
또한 함수 groupby는 agg와 함께 사용되어 각 열에 대해 다른 집계 함수를 적용할 수 있습니다. 아래 예시에서는 그룹 수준에서 평균 연령을 구하고 환자의 중위수(전체 데이터를 크기순으로 나열(오름차순, 내림차순 무관)했을 때 중앙에 위치하는 값) 체중을 구하는 것에 관심이 있습니다.
import pandas as pd
group = ['A', 'B', 'A', 'A', 'B', 'C']
age = [84, 61, 27, 75, 90, 56]
weight = [164, 189, 135, 121, 172, 138]
df = pd.DataFrame({'group': group, 'age': age, 'weight': weight})
df_grouped = df.groupby('group').agg({"age": lambda x: x.mean(),
"weight": lambda x: x.median()})
'''
df_grouped
age weight
group
A 62.0 135.0
B 75.5 180.5
C 56.0 138.0
'''5. 클로저(Closures)
짧고 간결한 구문으로 인해 람다 함수는 클로저라고 하는 중첩 함수 내에서 자주 사용됩니다.
간단히 말해서 클로저는 외부 함수가 닫힌 후에도 외부 함수의 변수에 액세스 할 수 있도록 합니다.
이를 설명하기 위해 클로저를 사용하여 사용자 정의 승수를 생성해 보겠습니다.
def multiplier(factor):
return lambda x: x * factor
double = multiplier(2)
triple = multiplier(3)
'''
double(10)
20
triple(2)
6
'''
여기서 multiplier 함수는 factor 변수를 "닫아주는" 람다 함수를 반환합니다. 구체적으로, multiplier가 인자 factor로 호출될 때, factor에 대한 참조를 함수 정의에 포함하는 새로운 함수가 생성됩니다. 이는 새로운 함수(double이나 triple과 같은 변수에 저장됨)가 나중에 어떤 인자 x로 호출될 때, 함수는 여전히 multiplier에 전달된 factor의 값을 액세스할 수 있다는 것을 의미합니다.
이 개념이 유용하게 적용되는 또 다른 예는 2차 함수를 푸는 것입니다. 이는 물리학에서 발사체의 궤적 계산과 같은 것에서 자주 사용되지만, 데이터 분석, 최적화 문제 및 신호 처리에서도 자주 사용됩니다. 가상 발사체의 운동을 설명하는 2차 함수의 일부 인위적인 예시를 살펴보겠습니다. 임의의 입력값 a, b, c는 각각 -50, 450, 0으로 선택되었습니다.
def quad_func(a, b, c):
return lambda x: a * x**2 + b * x+ c
f = quad_func(-50, 450, 0)
'''
f(0)
0
f(2)
700
f(4)
1000
f(6)
900
f(8)
400
'''
만약 0에서 9 사이의 값을 2차원 평면상에 나타낸다면 다음 그림과 같습니다.
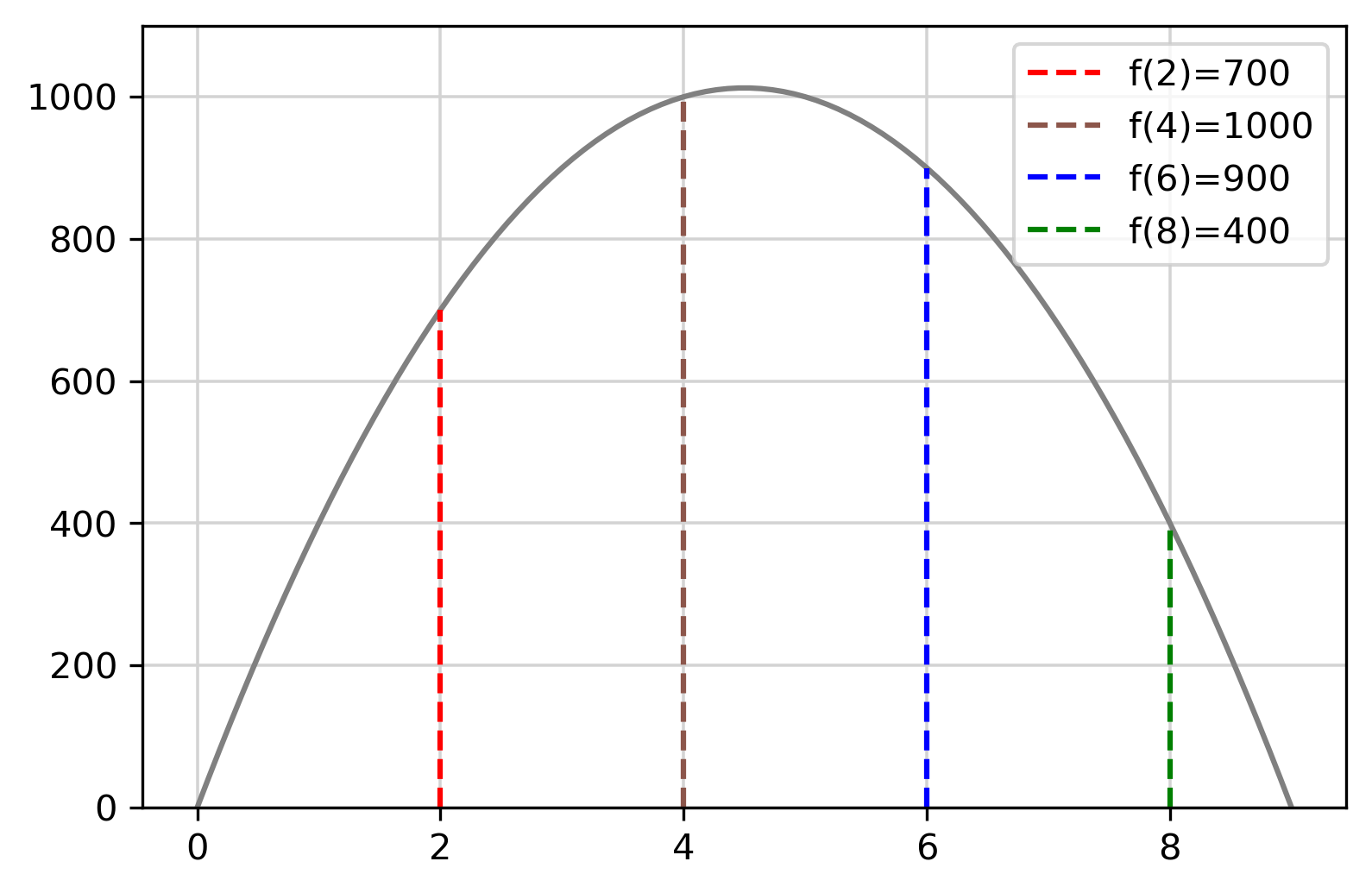
위의 그림을 그리기 위한 스크립트는 다음과 같습니다.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
mpl.rcParams['figure.dpi'] = 300
def quad_func(a, b, c):
return lambda x: a * x**2 + b * x+ c
f = quad_func(-50, 450, 0)
x = np.linspace(0, 9, 100)
y = f(x)
# Plot the function
plt.plot(x, y, c = 'grey')
plt.grid(True, linestyle='-', linewidth=0.85, color='lightgrey')
plt.ylim(0, 1100)
# f(2), f(4), f(6), f(8)에 대응하는 색상을 설정하기 위한 dict
color_dict = {2:'#ff0000', 4:'#8c564b', 6:'#0000ff', 8:'#008000'}
# Add vertical lines at the specified points
for x0 in [2, 4, 6, 8]:
print(x0, f(x0))
plt.axvline(x=x0, ymin = 0, ymax = f(x0) / 1100, color=color_dict[x0], linestyle='--',
label = 'f({})={}'.format(x0, f(x0)))
# Add a legend
plt.legend(loc = 'upper right')
# Show the plot
plt.show()
저도 람다 함수를 잘 사용하지 못해서 아래의 글을 보고 람다함수를 판다스 데이터 프레임이나 리스트와 결합해서 사용할 수 있는 방법을 크게 5가지로 정리해 보았는데요 (데이터변환, 필터링, 정렬, 그룹핑 및 집계함수, 클로저).
앞으로 저도 코드를 간결하게 작성하고 싶을 때 람다 함수를 더 잘 사용해보고자 합니다.
길고 두서없는 글 읽어주셔서 감사합니다. 😊
출처 : https://towardsdatascience.com/how-to-effectively-use-lambda-functions-in-python-as-a-data-scientist-fd6171554053
How to Effectively Use Lambda Functions in Python as a Data Scientist
An introduction to their syntax, capabilities, and applicability in data science
towardsdatascience.com
'Data Analysis' 카테고리의 다른 글
| [번역] 당신은 Train, Validation & Test Set을 올바르게 사용하고 있습니까? (0) | 2023.11.28 |
|---|---|
| Over Sampling for Regression (0) | 2023.11.01 |
| PCA(주성분분석) vs LDA(선형판별분석) 비교 (0) | 2023.01.27 |
| 분류 문제의 평가지표 (PRECISION, RECALL, ACCURACY 등) (0) | 2022.04.12 |
| [Python] iris dataset load & pre-processing (0) | 2022.02.10 |



